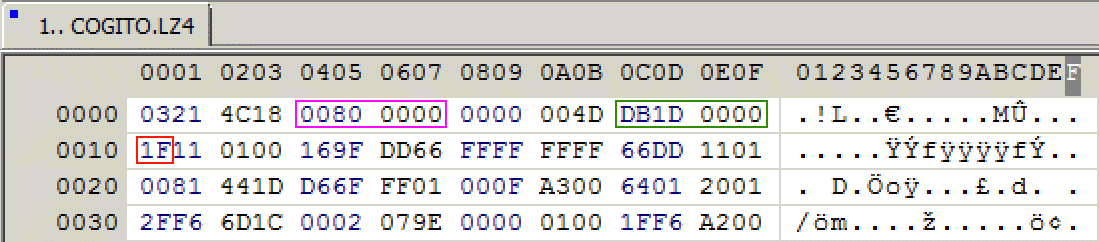
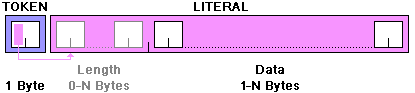
LZ4 Data Compression
(C) 2013 by Antoine VIGNAU and Olivier ZARDINI




| Apple
IIgs pictures, 320*200 pixels, 16 or 256 colors, 32 KB |
Pack Byte |
Dream Graphix |
LZ4 |
GIF |
 |
10
296 bytes 31,4 % 1 360 570 cycles 58,7 KB/s |
6
249 bytes 19,0 % 2 231 064 cycles 35,8 KB/s |
6
505 bytes 19,8 % 332 466 cycles 240,6 KB/s |
6 126 bytes 18,6 % 6 152 697 cycles 13,0 KB/s |
 |
26
375 bytes 80,4 % 1 068 277 cycles 74,8 KB/s |
21
815 bytes 66,5 % 4 871 780 cycles 16,4 KB/s |
23
517 bytes 71,7 % 388 026 cycles 206,1 KB/s |
19 545 bytes 59,6 % 8 958 474 cycles 8,9 KB/s |
 |
15
797 bytes 48,2 % 1 037 821 cycles 77,0 KB/s |
15
435 bytes 47,1 % 3 803 489 cycles 21,0 KB/s |
14
799 bytes 45,1 % 299 801 cycles 266,8 KB/s |
14 003 bytes 42,7 % 7 810 314 cycles 10,2 KB/s |
 |
5
589 bytes 17,0 % 1 060 387 cycles 75,4 KB/s |
3
625 bytes 11,0 % 1 801 482 cycles 44,4 KB/s |
2 800 bytes 8,5 % 273 653 cycles 292,3 KB/s |
3
355 bytes 10,2 % 5 633 328 cycles 14,2 KB/s |
 |
10
500 bytes 32,0 % 1 079 768 cycles 74,0 KB/s |
8
488 bytes 25,9 % 2 613 486 cycles 30,6 KB/s |
8
862 bytes 27,0 % 308 914 cycles 258,9 KB/s |
7 634 bytes 23,2 % 6 480 595 cycles 12,3 KB/s |
 |
11
236 bytes 34,2 % 1 380 135 cycles 57,9 KB/s |
6
908 bytes 21,0 % 2 346 779 cycles 34,0 KB/s |
6
651 bytes 20,2 % 332 758 cycles 240,4 KB/s |
6 510 bytes 19,8 % 6 249 860 cycles 12,8 KB/s |
 |
24
135 bytes 73,6 % 1 678 614 cycles 47,6 KB/s |
16
406 bytes 50,0 % 3 972 969 cycles 20,1 KB/s |
18
873 bytes 57,5 % 454 973 cycles 175,8 KB/s |
16 196 bytes 49,4 % 8 249 420 cycles 9,6 KB/s |
 |
22
842 bytes 69,7 % 1 581 637 cycles 50,5 KB/s |
12
657 bytes 38,6 % 3 349 851 cycles 23,8 KB/s |
7 659 bytes 23,3 % 337 687 cycles 236,9 KB/s |
15
275 bytes 46,6 % 7 970 263 cycles 10,0 KB/s |
 |
21
571 bytes 65,8 % 1 774 829 cycles 45,0 KB/s |
14 130 bytes 43,1 % 3 593 395 cycles 22,2 KB/s |
15
297 bytes 46,6 % 438 263 cycles 182,5 KB/s |
14
410 bytes 43,9 % 7 894 609 cycles 10,1 KB/s |
 |
15
635 bytes 47,7 % 1 280 057 cycles 62,4 KB/s |
11
876 bytes 36,2 % 3 214 526 cycles 24,8 KB/s |
13
099 bytes 39,9 % 373 387 cycles 214,2 KB/s |
11 010 bytes 33,5 % 7 163 882 cycles 11,1 KB/s |
 |
18
584 bytes 56,7 % 1 729 744 cycles 46,2 KB/s |
11
948 bytes 36,4 % 3 233 915 cycles 24,7 KB/s |
13
217 bytes 40,3 % 418 503 cycles 191,1 KB/s |
11 107 bytes 33,8 % 7 187 650 cycles 11,1 KB/s |
 |
14
285 bytes 43,5 % 1 519 662 cycles 52,6 KB/s |
8
729 bytes 26,6 % 2 658 058 cycles 30,0 KB/s |
9
970 bytes 30,4 % 385 497 cycles 207,5 KB/s |
8 003 bytes 24,4 % 6 552 497 cycles 12,2 KB/s |
 |
23
153 bytes 70,6 % 1 781 584 cycles 44,9 KB/s |
15
168 bytes 46,2 % 3 766 558 cycles 21,2 KB/s |
14 807 bytes 45,1 % 422 706 cycles 189,2 KB/s |
15
341 bytes 46,8 % 8 082 557 cycles 9,8 KB/s |
 |
26
166 bytes 79,8 % 1 347 634 cycles 59,3 KB/s |
17
923 bytes 54,6 % 4 259 943 cycles 18,7 KB/s |
20
258 bytes 61,8 % 470 362 cycles 170,0 KB/s |
17 049 bytes 52,0 % 8 410 343 cycles 9,5 KB/s |
 |
13
219 bytes 40,3 % 1 562 617 cycles 51,1 KB/s |
7
678 bytes 23,4 % 2 479 857 cycles 32,5 KB/s |
8
640 bytes 26,3 % 362 520 cycles 220,6 KB/s |
7 217 bytes 22,0 % 6 387 125 cycles 12,5 KB/s |
 |
22
741 bytes 69,4 % 1 082 730 cycles 73,8 KB/s |
14
622 bytes 44,6 % 3 679 626 cycles 21,7 KB/s |
18
471 bytes 56,3 % 395 589 cycles 202,2 KB/s |
14 606 bytes 44,5 % 7 934 587 cycles 10,0 KB/s |
 |
25
524 bytes 77,8 % 1 326 426 cycles 60,3 KB/s |
18
684 bytes 57,0 % 4 389 130 cycles 18,2 KB/s |
20
592 bytes 62,8 % 422 764 cycles 189,2 KB/s |
17 256 bytes 52,6 % 8 458 843 cycles 9,4 KB/s |
 |
23
288 bytes 71,0 % 1 653 214 cycles 48,3 KB/s |
14 427 bytes 44,0 % 3 647 405 cycles 21,9 KB/s |
16
303 bytes 49,7 % 453 836 cycles 176,2 KB/s |
14
683 bytes 44,8 % 7 954 603 cycles 10,0 KB/s |
 |
15
848 bytes 48,3 % 1 287 696 cycles 62,1 KB/s |
12
239 bytes 37,3 % 3 275 280 cycles 24,4 KB/s |
12
548 bytes 38,2 % 354 660 cycles 225,5 KB/s |
11 723 bytes 35,7 % 7 345 132 cycles 10,8 KB/s |
| Total /
Average |
346
784 bytes 55,7 % 26 593 402 cycles 57,1 KB/s |
239
007 bytes 38,3 % 63 188 593 cycles 24,0 KB/s |
252
868 bytes 40,6 % 7 226 365 cycles 210,3 KB/s |
231 049 bytes 37,1 % 140 876 779 cycles 10,7 KB/s |
